Python学习笔记 简单爬虫

一如既往不正经的前言
嘿嘿,我又回来了,今天在U盘里弄好了hexo,现在可以继续更新了
并且这次博客添加了访问量统计,欢迎扩~
那么,本期更新一个简单的Python爬虫
爬虫原理
小白: 大佬大佬~爬虫是啥啊?
大佬: 去搜索引擎查呀
小白: 查了,还是看不懂
大佬: emmmmm..那你继续往下看吧…
概述
2333,爬虫其实很好理解
我们都知道上网是用浏览器的,那么我们具体是怎样访问一个网页的呢?看下面吧(懒得画图了)
浏览器 –发送一个请求www.bing.com –>
服务器 <–接受到请求-–
服务器 –做出响应–> –返回数据–> 浏览器
什么?还是不了解?那我们用浏览器来看一下吧,我们随便打开一个网页
以Chrome/Chromiun为例,接下来依次点击 鼠标右键——检查——NetWork——将Preserve log打上勾 ,然后刷新 就会发现出现了以下内容
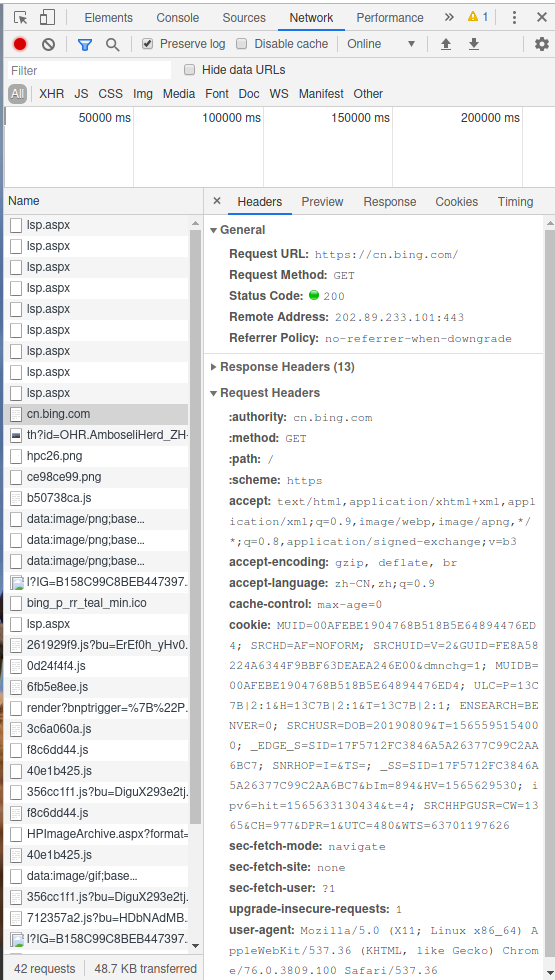
我们可以看到浏览器很详细的把请求内容显示出来了,而左边那些列表,你已经获取了这个网站的内容。
爬虫的原理就是把这些过程自动化,不需要我们去手动访问,就可以把网页中你想要的信息和内容爬取下来。
爬虫的作用
举个例子,这里有一个 全国号码段(链接已失效) 的网站,我们需要取一个城市中其中一个号码段的所有的号码。比如西安市
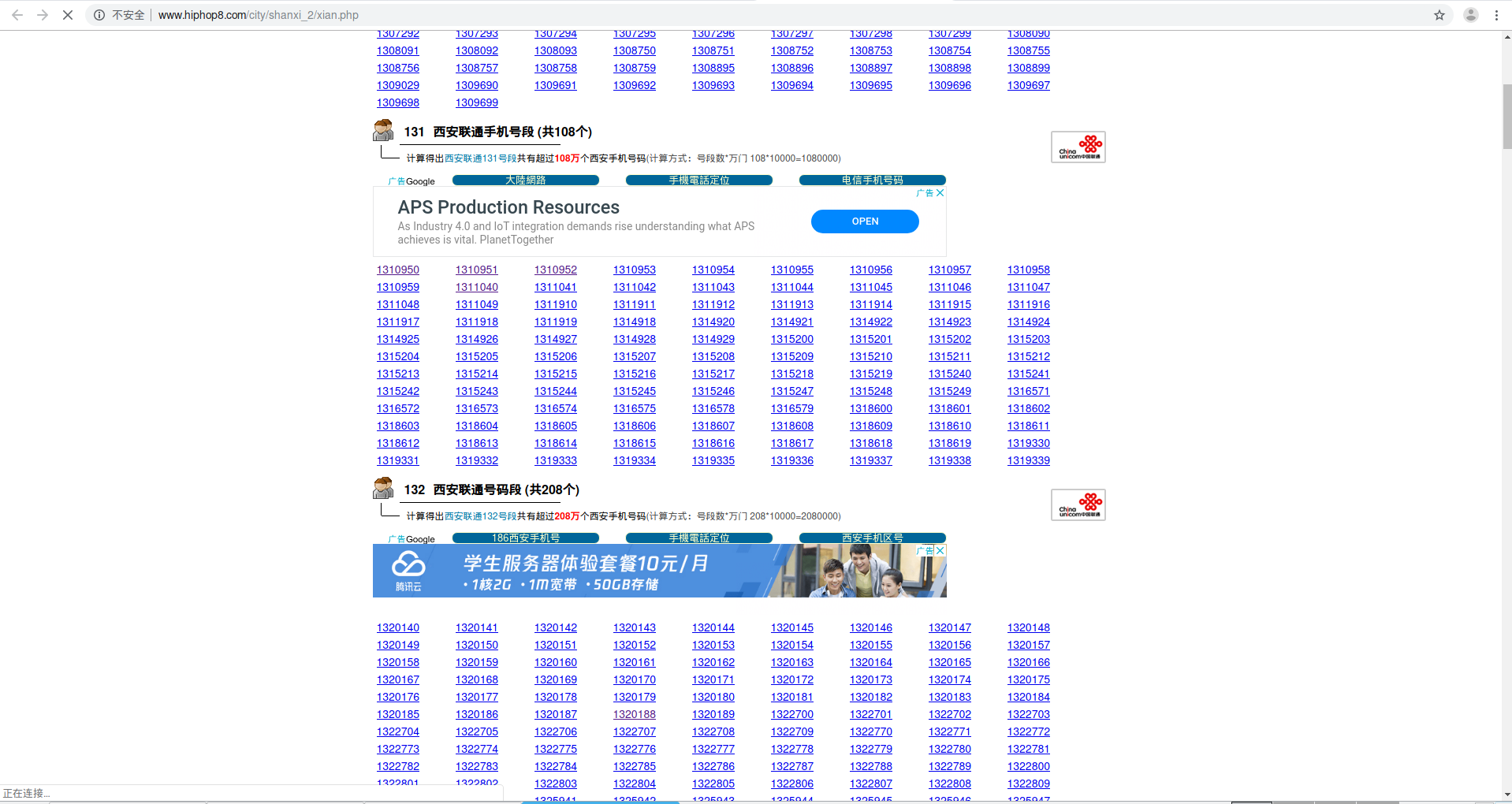

可以看到,号码段有很多,每个段有一万个号码。这个时候怎么办呢?总不可能用鼠标一条一条的去复制粘贴吧?这个时候爬虫就派上用场了。
其实也可以用来爬取我的博客,当更新的时候就可以及时收到更新信息
啊啊别打我,疼疼疼
编程语言的选择
我们如果要进行爬虫工作,那么就必须使用编程语言,用得最多的是Python,因为Python进行爬虫是比较简便的,当然也可以选择其他的比如C/C++、Java等,甚至是易语言都可以做到,只不过难易度和写法不同,目的和功能都是一样的。本期我们选择Python
Python的安装
Python是跨平台的语言,所以平台不同安装方法也有所不同。
Windows
可以到Python的官网去下载安装程序并安装,建议下载Python3
Mac OSX
同样到Python的官网下载
Linux
Linux则在包管理器安装即可
deb系
$ sudo apt-get install python3Arch系
$ sudo pacman -S pythonrpm系
$ sudo yum install python3Android
Android平台则安装QPython即可,
安装pip
Windows和Mac OSX的安装程序会自动装上pip,而Linux则不会,需要手动安装。
什么?你问我Android?我也不知道2333
首先打开这个网页,然后点击Download,下载第二个tar.gz文件,这是个Linux压缩文件。
然后解压它,就会得到一个pip-19.2.2目录
$ tar -xvf pip-19.2.2.tar.gzcd进去
$ cd ./pip-19.2.2下面有一个 setup.py 文件,用python执行它即可
$ sudo python setup.py之后就会自动安装好pip了。
需要安装的模块
我的爬虫用到了以下模块:
- requests,网页请求模块
- BeautifulSoup,分析模块
安装命令:
$ sudo pip install requests BeautifulSoup如果感觉到速度很慢,则参考这里更换国内镜像源。
代码公开
这里公开一下获取手机号的简单爬虫代码
from bs4 import BeautifulSoup
import requests
print("简易手机号码抓取工具 By WeepingDogel")
url="http://www.hiphop8.com/mobile/xian_1319339.html"
page=requests.get(url)
page_info=page.content
soup = BeautifulSoup(page_info, "html.parser")
numbers = soup.find_all('a')
with open("1319339.txt","w") as file:
for number in numbers:
print(number.string)
file.write(str(number.string)+"\n")将代码复制到一个py文件中运行或修改即可。
最后
写得比较仓促,所以可能不够详细,请谅解。下方有评论区,欢迎评论(Tu Cao)。